Tal y como os comentaba en la primera entrega de esta serie de artículos sobre DRBD, en esta segunda entrada os explicaré un poquito la configuración más básica que hace falta para ponerlo en funcionamiento, así como los principales modos de funcionamiento que nos puede ofrecer.
Tal y como comentaba anteriormente, la configuración se puede realizar actualmente desde entorno gráfico, aunque para los más puristas y que quieran tener el control absoluto sobre todas las configuraciones posibles, la opción será sin duda mediante un archivo de texto con la configuración deseada. Aquí os presento el ejemplo más básico de dicho archivo y qué datos mínimos nos harán falta (en este ejemplo se van a replicar 2 volúmenes, para ver que la configuración es igual de sencilla sin importar el número de dispositivos a replicar).
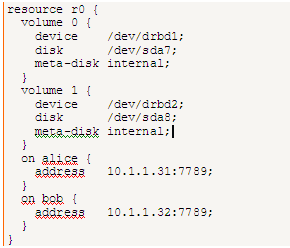
Como podemos observar, hemos creado un “recurso” llamado “r0”. Dentro de dicho recurso nos creamos los “volúmenes” a replicar con sus datos, así como las direcciones IP y puertos por los cuales se realizará la replicación. Podíamos haber creado los volúmenes como recursos independientes. La ventaja de hacerlo de esta segunda manera, es que podemos detener la sincronización del recurso “r0” y seguir realizando la réplica del recurso “r1” por ejemplo, mientras que si los configuramos como en el ejemplo, si detenemos el recurso “r0” se detendrá la réplica de ambos volúmenes. Esta configuración queda a elección del administrador del sistema, pudiendo hacerse como mejor le convenga. Como ya he comentado, podría tener todos los “recursos” que necesitase en el mismo archivo de configuración, aunque luego podría detener o iniciar los que quisiese.
En “device” especificamos el nombre que daremos al nuevo dispositivo, y podemos llamarlo como mejor nos parezca para luego identificarlo correctamente. Esto quiere decir que si lo llamamos “drbd1” como en el ejemplo, nos aparecerá una nueva entrada en el directorio “dev” con ese nombre y, a partir de ese momento, para acceder a dicha partición ya no accederemos mediante /dev/sda7, sino mediante /dev/drbd1 (esto es a todos los efectos, es decir, cualquier aplicación de nuestro sistema que tuviese que acceder a sda7, ya no lo podrá hacer, siendo esta partición accesible mediante el nuevo nombre drbd1). La partición sigue siendo accesible por cualquier software igual que si fuese la partición original.
Mediante el parámetro “disk”, especificamos la partición, disco, LVM… “real” que queramos replicar mediante el nombre “drbd1”.
En “metadisk” especificamos dónde estarán los metadatos almacenados y, casi siempre, serán “internal” tal y como he comentado antes.
Sólo nos queda especificar en ambos nodos (“bob” y “alice” para nuestro ejemplo) mediante qué IP (ya que puede y debe tener más de una tarjeta de red) y puerto se realizará la sincronización. Para el puerto, también podemos utilizar cualquiera, siempre y cuando no esté utilizado previamente por otra aplicación. Hay que tener en cuenta, que si separamos los volúmenes en recursos distintos, podemos utilizar un puerto para cada uno también, separando así los tráficos de réplica por puertos distintos.
Como podemos observar, los nodos se identifican mediante nombre, no mediante IP, por lo que es importante previamente haberse asegurado de que esto es posible (acceder por nombre desde un nodo al otro), ya sea añadiendo la entrada al archivo “hosts” o mediante DNS.
Simplemente con esta sencilla configuración y levantando el servicio de DRBD, ya tendríamos los discos replicándose en tiempo real. Podríamos tener una aplicación que guardase la información en el disco del nodo “bob” y automáticamente serían replicados por red al nodo “alice”. En cualquier momento que el nodo “bob” fallase, tendríamos disponibles los datos en el otro nodo (“alice”).
A parte de estas configuraciones básicas, hay muchas más que por ahora no entraré a comentar, como por ejemplo el “modo de funcionamiento”. El nodo principal manda el dato al secundario y lo da por escrito sin confirmación, o si queremos más seguridad podemos hacer que no se dé el dato por escrito hasta que no haya confirmación por el nodo secundario, haciendo el entorno mucho más seguro.
Evidentemente, ésta configuración es muy básica y sencilla. Pero para conocer la herramienta es suficiente. Una vez que sepamos manejarlo, podemos “complicarla” todo lo que queramos y necesitemos.
Por ejemplo, los nodos suelen funcionar en un entorno “Activo/Pasivo”, es decir, uno de los nodos es el que está accesible por las aplicaciones y “montado” en “lectura/escritura”, mientras el otro nodo está en modo “pasivo” y no accesible. En el momento que el primario cae, el secundario lo “promovemos” a “activo” y ya lo tendríamos accesible en modo “lectura/escritura”. Esta “promoción” habría que realizarla a mano, con el consiguiente riesgo de perder tiempo y datos mientras se realiza.
Para evitar esta situación, se podría configurar un entorno “Activo/Pasivo” gestionado mediante clúster, así si el nodo principal cae, automáticamente el clúster se encarga de promover el nodo “Pasivo” a “Activo”, minimizando el riesgo de perder información así como el tiempo en tenerlo operativo, ya que sería instantáneo. Si queremos rizar más el rizo, podemos plantear un entorno “Activo/Activo”, en el cuál ambos discos estuviesen montados a la vez como “lectura/escritura” y que automáticamente al caer uno de los nodos, el secundario fuese accesible directamente.
Estas configuraciones ya no son tan triviales, y requieren de algo más de configuración para llevarlas a cabo, como por ejemplo crear el disco drbd como dispositivo ISCSI y asignarle una IP. Tanto el dispositivo ISCSI y la IP se pueden configurar como recursos de un clúster y, si un nodo cae, automáticamente la IP y el acceso ISCSI pasarían al segundo nodo, proporcionando un entorno de alta disponibilidad y tolerancia a fallos. Tal y como comento, estas configuraciones ya no son tan sencillas ya que, por ejemplo, para tener ambas particiones accesibles al mismo tiempo en “lectura/escritura” habría que formatearlas en un sistema de archivos que lo soporte, como por ejemplo ocfs2 (Oracle cluster file system, versión 2).
Además, si la conexión entre nodos cae y tenemos configurado el entorno en “Activo/Activo”, podríamos tener una aplicación que corriese en ambos nodos simultáneamente que diese por desaparecido al otro nodo, accediendo cada aplicación a su disco pensando que el otro nodo ya no está accesible, teniendo así una situación de “Split-brain” (datos distintos en los discos), llegando a resultar peligroso para la integridad de los datos.
De todos modos DRBD está preparado para estas situaciones, y tiene “reglas” que podemos configurar para auto-resolver este tipo de situación, como por ejemplo descartar automáticamente los datos más antiguos, que siempre un nodo se considere el que contiene los datos buenos y sobreescriba los datos del otro nodo… Aunque sin duda alguna, si llegamos a esta situación, la mejor opción es no hacer una reconexión automática y realizarla a mano, así nos aseguraremos de que descartamos los datos que realmente haya que descartar.
Como punto final comentar que, evidentemente, DRBD está preparado perfectamente para auto-reconectar si uno de los nodos se apagase, se reiniciase o perdiese la conexión de red, replicando los datos pendientes automáticamente en cuanto el fallo se restableciese (para entornos “Activo/Pasivo”. Para entornos “Activo/Activo” habría que contemplar las reglas mencionadas anteriormente).
Creo que como introducción a la herramienta, es suficiente. De todos modos en las siguientes entradas os presentaré una configuración real que está en producción ahora mismo y que seguro que os hará comprender mucho mejor las posibilidades que nos brinda esta magnífica herramienta.
Por supuesto, si alguien está interesado en ampliar conocimientos sobre DRBD, estoy disponible para cualquier duda que tengáis.
Saludos y hasta la siguiente entrada.